Yudit HOWTO
HOWTO Document List
You can see the howto documents in Yudit unicode editor if you type 'howto configure' in the command area of the editor window.
For your reference, I put the following documents on this server:
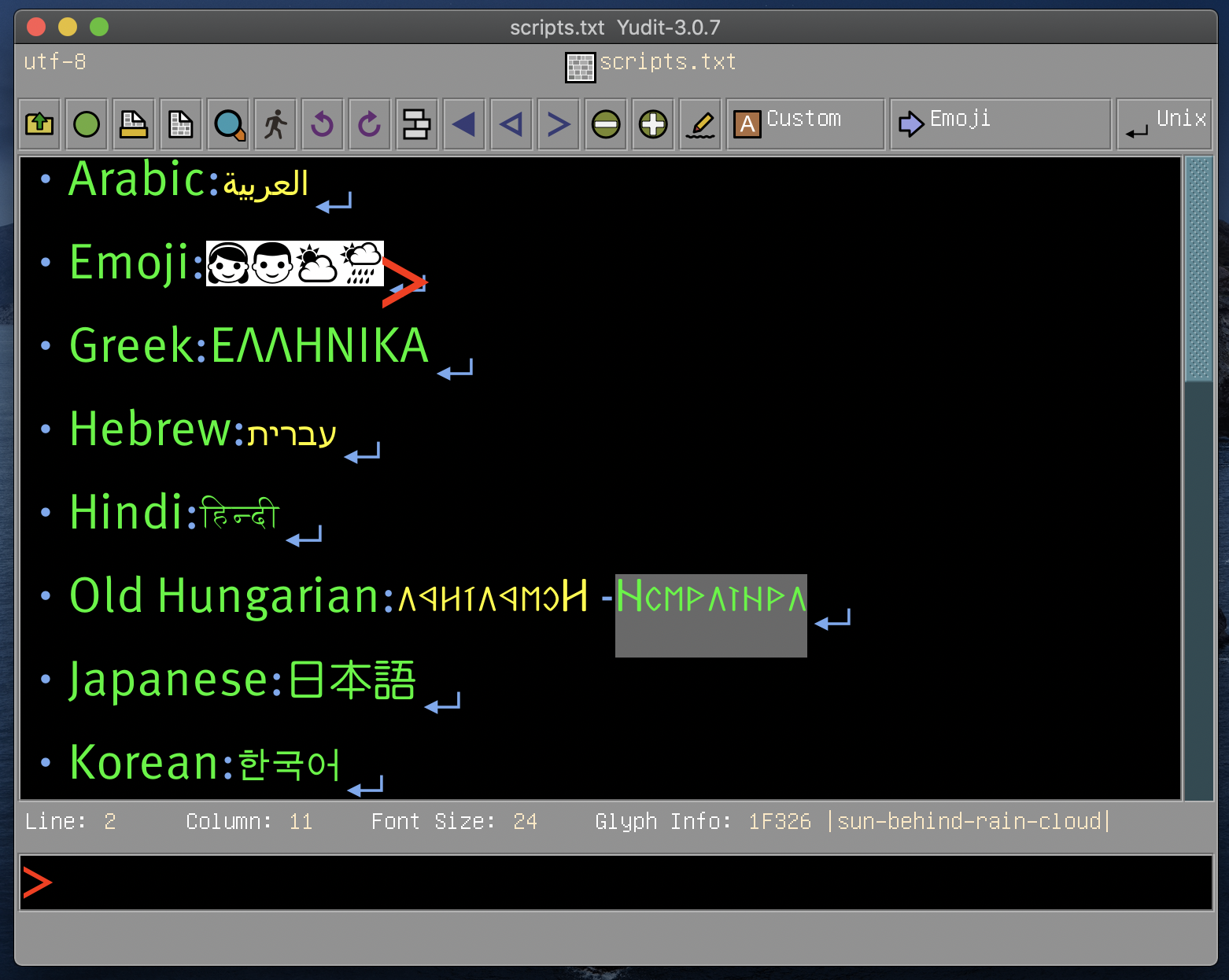
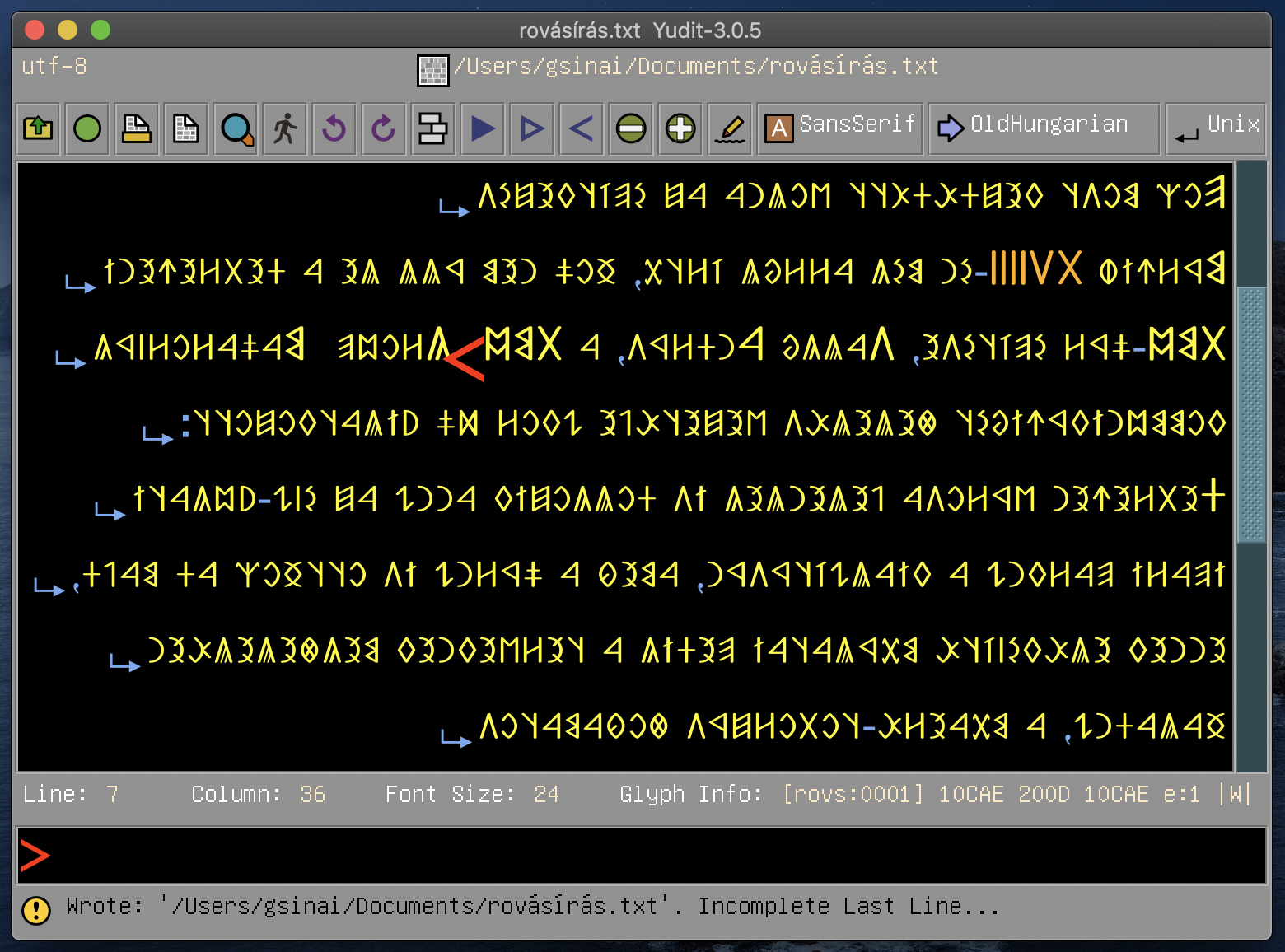
arabic, baybayin, berber, bidi, build, configure, devanagari, freehand, georgian, greekancient, japanese, keymap, malayalam, rovasiras, syntax, tamil, tibetan, vietnamese, windows
HOWTO freehand
Description
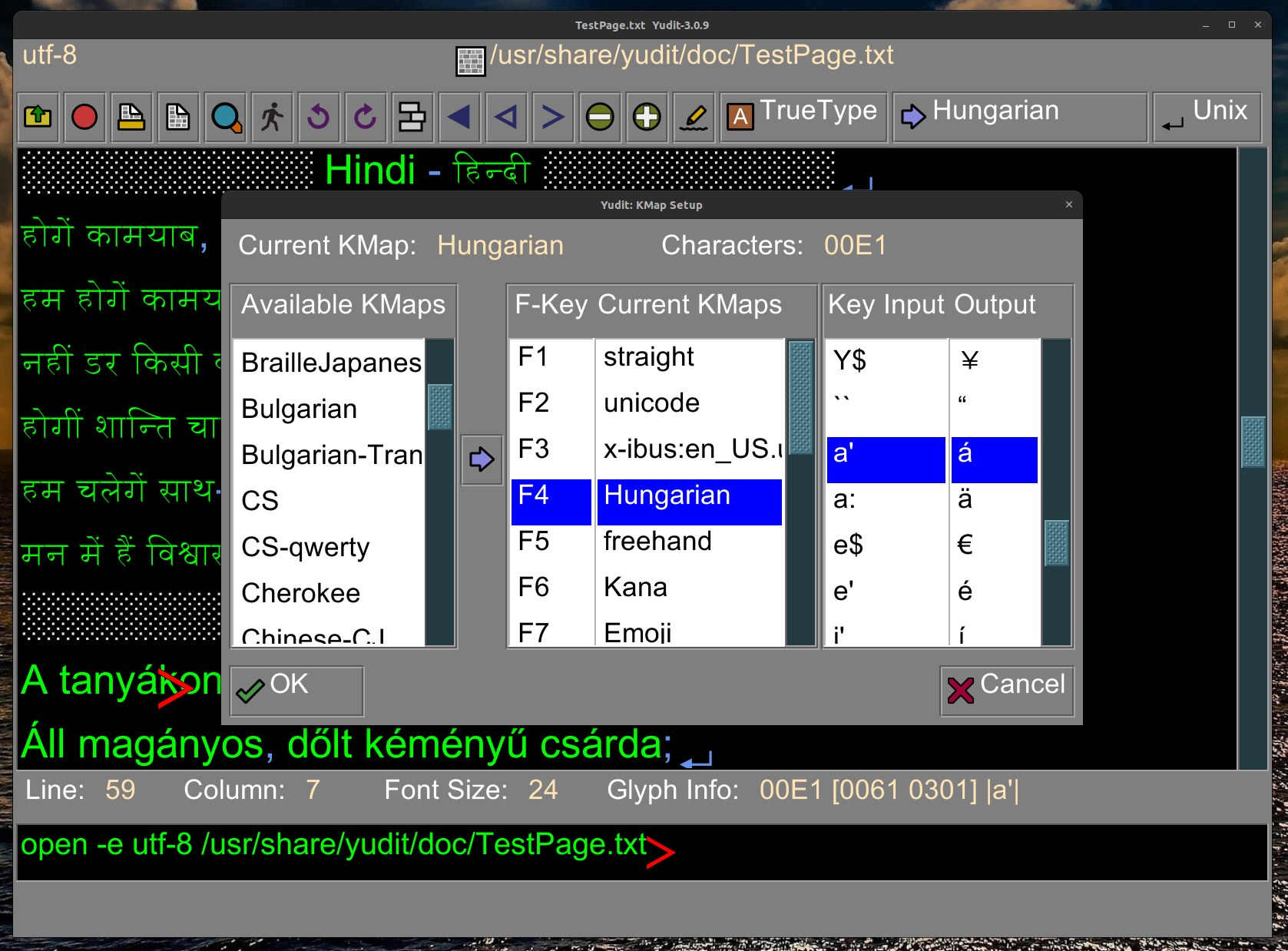
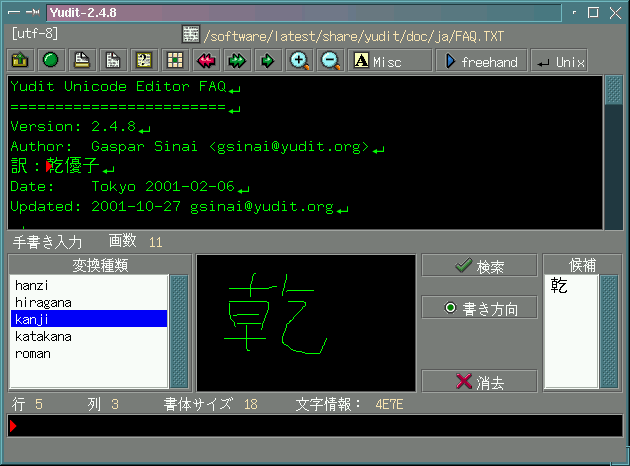
For Yudit a new input method was added. It is
called freehand and it can be configured just
like any other input method (top menu).
The original The handwriting recognition algorithms
were made by Todd David Rudick (in Java) for his
program JavaDict:
http://www.cs.arizona.edu/japan/JavaDict/
For Yudit a new algorithm was developed, based upon
the old idea. Yudit uses outside files for handwriting
recognition. The file format is very simple, all you
need is a utf-8 enabled text editor - Yudit to create
one. The extension of these files is .hwd. Two file
format versions are recognized: '#HWD 1.0' and '#HWD 2.0'.
You have to put this mark at the beginning of each
hwd file. The recommended file format is 2.0. 1.0 format
was kept because JStroke files and gtkkanjipad files
can be converted to 1.0 format only, so you can use them
in Yudit. I Yudit comes with
kanji.hwd - converted from JStroke
http://www.wellscs.com/pilot/
hanzi.hwd - converted from gtkkanjipad
http://www.kotnet.org/~skimo/kanji/
If you notice some error in data please send me the description
of error. I already have one patch for kanji.hwd in mytool/hwd.
Version 1.0 Yudit files can not be converted from one to another
because the use different angles (32 vs. 12).
When making a hwd file please be aware of the limitation imposed
by the handwriting recognition algorithm:
a) Strokes have a specific order. If you write something in
a different order, the algorithm will ignore it.
b) Recognition work with angle-order. If two glyph have the same
or similar angles. Just a few additional flags are available
to specify relative positions.
The following files are shipped with 2.4.8 and they are made
by Inui Yuko.
hiragana.hwd
katakana.hwd
If you create such files please put the in share/yudit/data or your
~/.yudit/data.
Algorithm used in freehand input (Yudit specific)
The scalar product of the unit vector described in the
guide and the vector drawn on the screen is calculated.
Please note that this number could be negative if the strokes
are in the opposite direction. In case Yudit's 'directed'
flag is used, we assume the stroke has been drawn in
the opposite order and we re-apply the algorithm with
the lines drawn in the opposite order.
In case of multiple vectors in the guide vector array
Yudit tries to subdivide the lines with moving point maximize
the scalar product. The longer the length is the closer
we are to the guide. You see, the maximum value of the
scalar product is the length of the line multiplied by the
unit vector's length, and this happens if the strokes
can exactly be aligned to the guide.
Extra Hints
The original algorithm added some hints in case directionality
is not enough. This algorithm does it too. Use this if
it is absolutely necessary.
Add fuzz with the flags, winner is the one that has
length-of-projection) +/- fuzz
largest.
Please note that the real-length is constant for the full stroke.
so this method really gives us the best candidate.
The length of projection can never reach full-length.
They can be equals at most.
Data file format
I think it is better if I start with a real file (please remove leading
spaces)
#HWD 2.0 DO NOT REMOVE THIS LINE
# roman.hwd Gaspar Sinai <gaspar (at) yudit.org>
# Roman Letters for Yudit freehand
01 C 8-6-4
02 A 1-5,3
02 B 6,4-7-4-7
The file has a header. It must start with '#HWD 2.0'. Lines
starting with '#' are comments. subsequent lines are broken into
3 words, separated by ' ' (not double-width) space.
1. The number of strokes in the character. I use leading zero
for easy sort. Data needs to be in ascending order.
2. The utf-8 encoded character or string
3. Guide
Guide
This tells Yudit how you draw the character. Each stroke is
separated with commas.
You always have to imagine that a vector array will be matched
to the drawing, and that should become as close to the pattern
as possible. Still, do not try to over-describe the character.
In the example I described 'C' like this. Go toward 8 o'clock
then from the new point go toward 6 o'clock, then from the point
you are at, go in the direction of 4 o'clock.
You don't really need extra flags, but if you ever need them it
looks like this:
02 X 5,7 | j2-b1
02 Y 5,7
This calculates (stoke.2.end.y) - (stroke.1.mid.y). We work on
screen coordinates, where origo is upper left corner of the screen,
so this number will distinguish X. You can emphasize a filter by
putting a '!' at the end:
j2-b1!
and you can specify multiple filters, separated by spaces (' ').
Flag names
x x-start
y y-start
i x-end
j y-end
a x-middle
b y-middle
l length
In case you made a cool *.hwd please send it to me.
Gaspar Sinai <gaspar (at) yudit.org> Tokyo 2006-05-21



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}